
2022年11月末にリリースされたSDv2(sd v2.0)は、SDv1.xからどのような改善がされたのか、5種類のうちどのモデルを使えばいいのか、sd-v2.0.ckpt(モデルファイル)のダウンロード&webUI(1111版)での使用方法を画像付きで丁寧に解説します。

SD v2はSD v1.xからどう進化したのか
この記事の内容は以下の公式ソースを出典として情報の正確性を重視していますが、私の英語力に拠る誤りがあるかもしれません。
もし誤り等ございましたら遠慮なくご指摘くだされば幸いです。
huggingface🤗公式:

 huggingface.co
github公式:
huggingface.co
github公式:

 github.com
開発元公式ブログ:
github.com
開発元公式ブログ:

 stability.ai
stability.ai主なアップデート内容とその理由を簡潔にまとめました。
- SD v2テキストエンコーダーを刷新して画像品質向上
- SD v2.0は新たなテキスト エンコーダー 「OpenCLIP」を使用
- SD v2は非常に厳格なNSFWフィルターを通過したデータセットで学習
- SD v2はアダルトフィルタが強いため、SD v1.x系列でNSFW画像を出せた呪文を入力しても、意図通りの描写はされにくい😰
- 512×512,768×768の2つのデフォルト解像度をサポート
- 従来より高画質な画像の生成精度が向上
- 従来形式のモデルの他に、以下の用途特化モデルをリリース
- image2image用、深度条件付きモデル:プロンプトと深度情報を元に画像生成するモデル
- inpaint専用モデル:画像の特定の要素(背景のみ、メガネのみ、服装のみなど)を差し替えることに特化してモデル
- 超解像アップスケーラー専用モデル:高品質な4倍アップスケーリング用モデル
個人的には、基本解像度が768×768でトレーニングされたというのが特に驚きですね!
これから先、私のようなローカル勢はますますGPUちゃんをアツくすることでしょう。ハードウェア負荷的に…
v2.0 512×512モデルについて
Stabele Diffusionv2の512-baseモデルは、なんとSD v1.xの追加学習ではなくゼロからの学習モデルです!!!
- ポルノ排除済みデータセット(解像度256×256)で550,000ステップ学習
- 同じデータセットの512×512解像度版でさらに850,000ステップ学習
ファイル名:512-base-ema.ckpt(5.21 GB)
SHA256: d635794c1fedfdfa261e065370bea59c651fc9bfa65dc6d67ad29e11869a1824

v2.0 768×768モデルについて
768×768モデルは、Stable Diffusion v2 base(512-base-ema.ckpt)をベースにして150,000ステップのトレーニングを行ったモデルに、768×768サイズの画像で更に140,000ステップ学習を行いました。
つまりこのように学習したわけです。
- ポルノ排除済みデータセット(解像度256×256)で550,000ステップ学習
- 同じデータセットの512×512解像度版でさらに850,000ステップ学習
- 同じデータセットをv-objectiveを使い再度150,000ステップ学習
- さらに別のデータセット(解像度768×768)で140,000ステップ学習
手間暇が凄い。手塩にかけて育てらてた768-v-ema.ckptを大切に使いたい。
ファイル名:768-v-ema.ckpt(5.21 GB)
SHA256: bfcaf0755797b0c30eb00a3787e8b423eb1f5decd8de76c4d824ac2dd27e139f
SD v2 モデル.ckptファイルのダウンロード方法
「Hugging Face🤗」のアカウントは必須ではないようです。
モデルに応じてファイル配布場所が異なるので、目的に合わせて選択します。
SDv2.0モデルは、以下の5種類あります。
単純にtext2image(文章から画像生成)では、1,2番目を使います。
- 512×512モデル(Stable Diffusion v2 base)
- 上記を元にした768×768モデル(Stable Diffusion v2 768-v-ema.ckpt)
- image2image用深度条件付きモデル(Stable Diffusion v2 depth)
- インペイント用モデル(Stable Diffusion v2 inpainting)
- アップスケーリング専用モデル(Stable Diffusion x4 upscaler)
- 手順1モデルの概要ページにアクセス
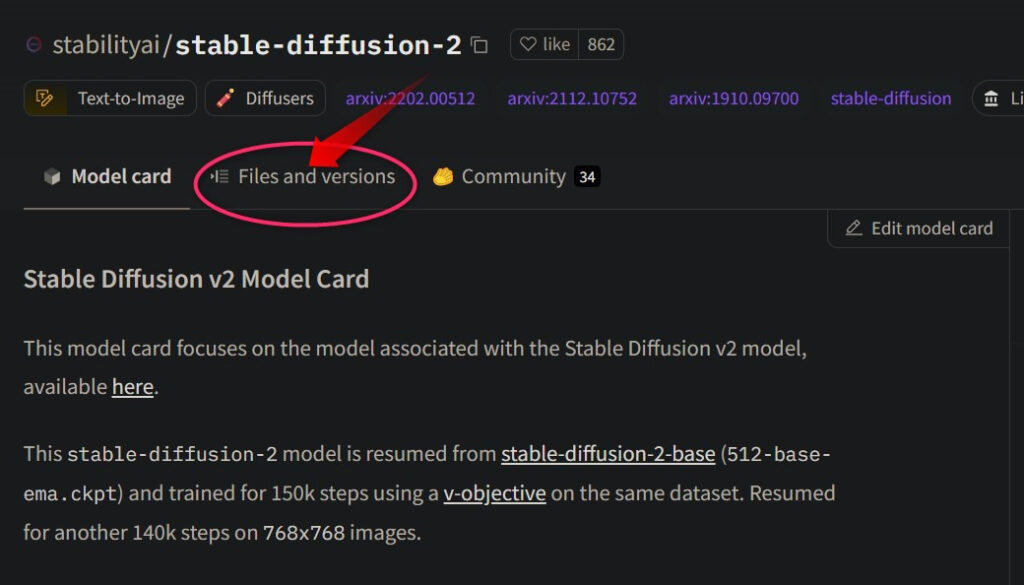
「Files and versions 」をクリックしてファイル一覧に移動します
- 手順2目当ての.ckptファイルを選択
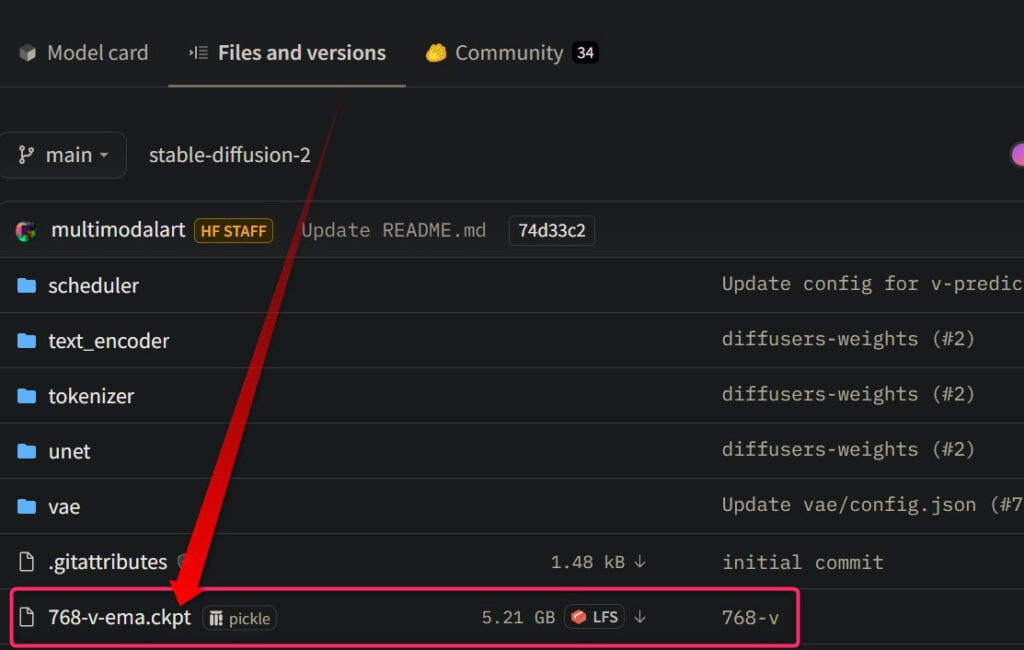
欲しいモデルの名前をクリックします
- 手順3ダウンロード実行
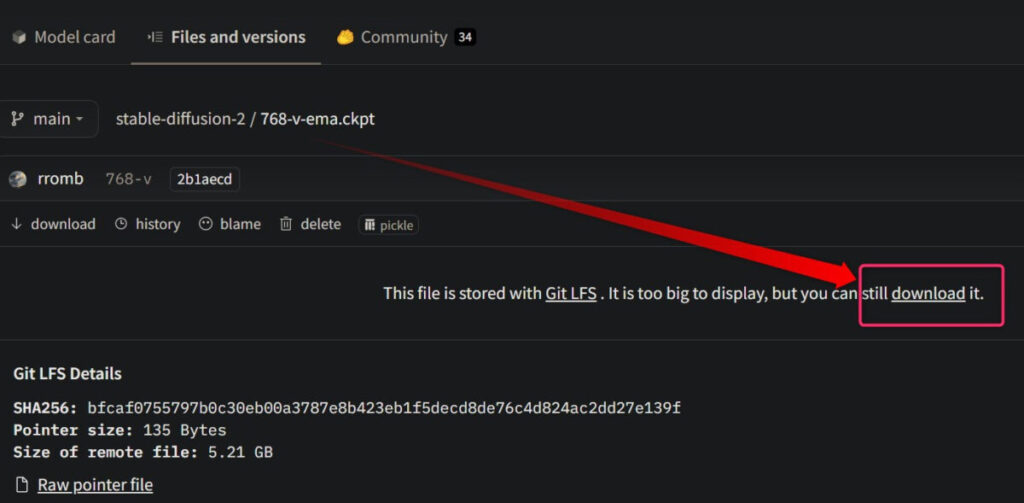
あとは「Download」をクリックすればOK
ファイルサイズがSD v1.x系よりも約1GB大きいため、気長に待ちましょう
- 手順4完了!



SD v2.0をStable Diffusion WebUI(AUTOMATIC1111)で使用する方法
ダウンロードしたckptファイルをモデルフォルダ内に移動します。

モデルは通常「C:\(中略)\stable-diffusion-webui\models\Stable-diffusion」に配置します。
その後、yamlファイルをコチラからダウンロードし、「768-v-ema.yaml」にリネームして、ckptファイルと同じフォルダ内に配置します。
そして、いつも通り「webui-user.bat」をクリックしてwebuiを起動します。
あとはモデル選択欄で「768-v-ema.ckpt」「512-base-ema.ckpt」等を選択すればOK。

よくある不具合の解消法

もし「Error」となった場合、おそらくwebuiのバージョンが古すぎるのが原因のため、以下の手順通りにアップデートをしてください。

アプデ後も変わらずErrorが出る場合は、海外の有能ニキたちが改善してくれるのを待ちましょう。自力でなんとかできる方は、是非プルリクエストしてください!!
WebUI(1111)リリース直後のような数分ごとに更新される状態ではないものの、1週間も待てば大抵改善されてます。
以上。
SD v2.0の主な改善点と使い方の解説でした。
追記:SD v2.1がリリース! SD v2.0公開後僅か10日あまりでアプデ!
SD v2.1に関する解説や使い方、どこが新しいのかはこちらの記事にまとめました。

AI関連記事まとめ
webUI(1111)ローカル関連(win10/win11向け)
グラボをまだ持っていない、買い替えたいが選ぶ基準がわからない!という時はこちらをご覧ください。

わかりにくいwebUI(1111版)のアップデート手順を丁寧に解説した記事もごらんください
モデルマージ関連

配合に用いたモデルはこちらからダウンロードリンクを探せます。

DreamBoothでファインチューニングする


ツールやtips,モデルがまとまっているページを探す
有用なリンク集・備忘録です。

声優を学習した音声読み上げAI MoeGoe GUI(Windows向け)
GUIで手軽に導入でき、どんな台詞も好きなキャラに読み上げて貰えます。

GPT2日本語生成モデルをWindowsで試す

{kind=link}
その他AI関連記事
